
The Challenge of Real-Time Data Streaming for Trading
Broadcasting platform is a system that receives events from a stock exchange and sends it to traders.
Last traded price (LTP) of TCS is powered by broadcasting system.

Order list is also powered by broadcasting system.

Broadcasting system also powers features like price alerts too.
In order to be future ready, we wanted to ensure that Broadcasting system:
- System has to be super fast.
- Should be able to handle 30K concurrent users
- Should be able to handle 200K messages / Sec from different exchanges.
- Is always sending latest data and does not send stale values
- Reduces packet drops. Packet drops in broadcasting platform is catastrophic. For example, a share hit 52 week high. If broadcasting system misses this packet then broadcasting system will show wrong 52 week value. A packet drop can happen when a trade packet lands on a network port but platform is slow enough to not read the message. By the time, source reads from network port the older trade packet is replaced by a new trade packet.
Broadcasting Design principles
The broadcasting system was designed with only 2 objectives — to be Stable and Fast.
For this couple of design principles were chosen which formed the basis of our design choices
- Compute is cheap. Prefer Speed over compute — This means system chooses to do same compute multiple times if network latency is reduced.
- Stale events are not always needed — Suppose a script xyz’s LTP (Last traded Price) was 100, 101 and 102 at T1,T2 and T3 time. It is okay to discard prices 100 and 101 and directly show price 102. Because user would not be interested in stale prices of the customer. But this is not in true in few of the cases which we will cover later.
- Multithreading is the key — It was envisioned from the begining that broadcasting platform should be 100% multithreaded. Nowhere in the ecosystem we have a single threaded component. One challenge was what if script id xyz updated twice in a second, let us call M1 (price changed to 100) and M2 (price changed to 101). If for some reason M2 is processed before M1 in a multithreaded, a custom chronological manager was made in Golang and its package will be opensourced soon.
- Anything and everything can fail — Every component has to have a secondary instance which can serve within few second in case the primary instance fails.
- Single responsibility principle to be adhered always. Broadcasting system should deal with only broadcasting and nothing else.
Design of SMC Low-latency Data Broadcast System
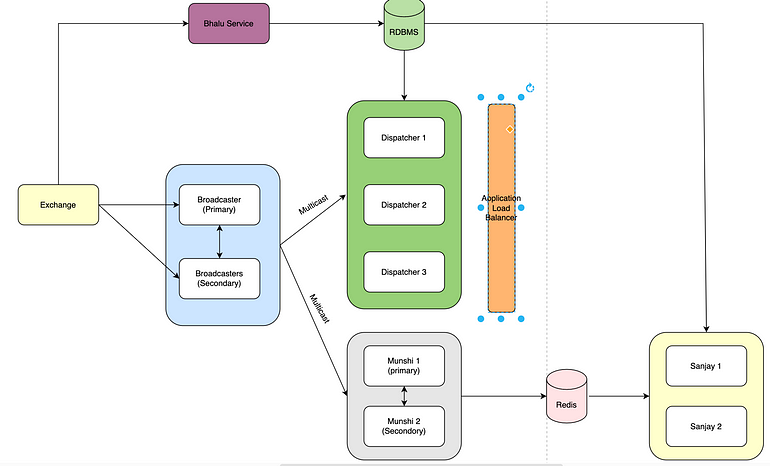
Choosing GoLang
Multiple programming languages were tested and proof of concepts resulted in Golang performing the best in our use case because :
- Golang was faster than java and python by 200% and 175% respectively. But 37% slower than Rust
- Unlike Rust, Golang had a self managed memory management with its own garbage collection.
Considering that we were building broadcasting for a retail client, we had the luxury of choosing golang for its memory management rather than Rust.
Moreover, Golang could handle 10,000 concurrent threads seemlessly with each thread processing atleast 5 messages in every second.
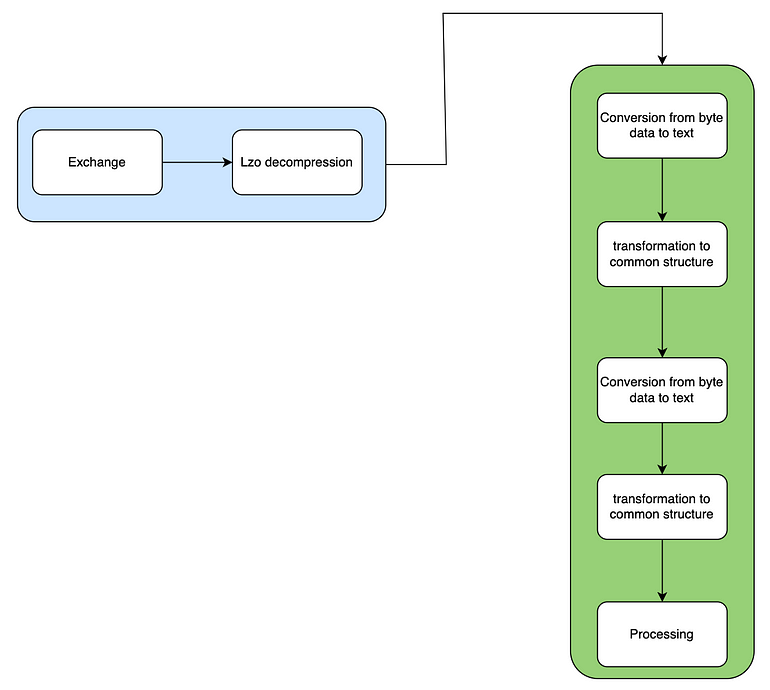
LZO Decompression (Our first compromise)
NSE uses a lossless data compression known as LZO compression. Though it saves network time, we could not find a working package in Golang which reliably decompressed the compression system. It was decided to write decompression of NSE events in cSharp. A language that is slow but could decompress LZO based compression.
Choosing Speed over compute
National stock exchange sends its data packets in compressed format.
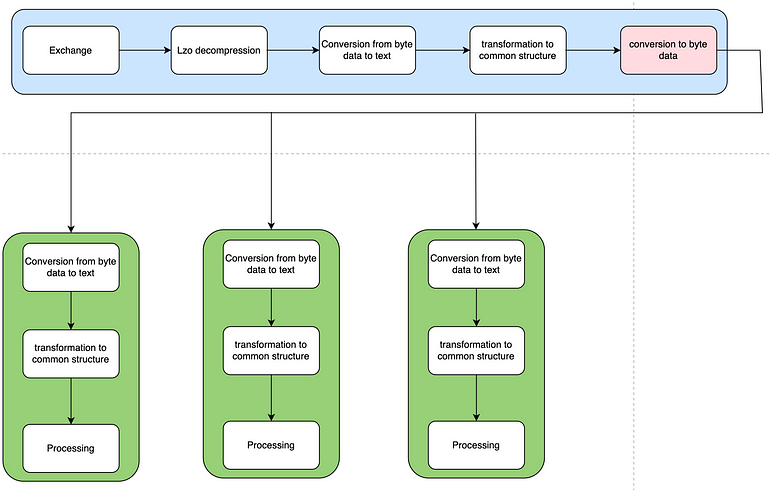
It was decided to decompress the message and send message directly to dispatchers without decoding the messages. This will save us the latency by eliminating the step to convert text data to byte data
Solving packet drops in data broadcast
At this stage we were seeing around 50% increase in packet drops. First challenge in this problem was to identify where packet drops were happening.
The major contributor in our case was multicast communication between broadcaster and dispatcher. Whenever a data packets land on a network card it gets to a processor in the core. This means, if other cores of the processor needs to utilize these messages there needs to be a context switch from one core to another. In order to mitigate this, we introduced parallel processing at the network level. Instead of 1 network connection we utilised multiple multicast connection.
Performance monitoring and benchmarking
Though broadcasting system was fast and but we needed to quantify it and send out alerts if slowness is observed. Problem is that traditional systems rely on IO operations to monitor things. This was unaffordable in our use case where 200K messages are intended to be processed.
To mitigate this, we calculated P99 values in memory and logging it after consistent intervals. Each message registers a compute time with a utility that is in memory. Moment 10K messages are processed or 20 seconds is elapsed , whichever is earliest, we log the P99 values and send data to greylog.
Making systems resilient
Current system has broadcaster which consumes data platform from exchanges. This is a single point of failure in the system which once failed, will stop the entire system. But if a failover mechanism is built, we can endup having duplicate data in the feed and overall cascading failures to downstream system.
In order to mitigate this, we created a system in which we had multiple instances of broadcaster in active — Dormant mode. Dormant broadcaster keeps on pinging active broadcaster to check if broadcaster is alive. Moment dormant broadcaster detects failure of active broadcaster, it itselfs assumes the role of active broadcaster. Once previous instance comes back up, it checks if there is an active broadcaster or not. If there is one, then it assumes the role of dormant broadcaster.
Next Steps
We plan to write a custom LZO decompression in go lang which will reduce the compute latency by 32 ms. This will reduce compute latency by 80%.
Also we plan to reduce network latency by introducing compression for folks who are in low network area but have a high compute device. Moreover, a lite version of app and broadcasting is planned with lesser data to be sent.
We are planning to migrate broadcasting system to cloud.
This article was originally published on Medium.